发布日期:2026-03-14 14:02 点击次数:174


写在前边
若是你正在构建RAG系统,大约你的业务波及图文、视频、音频等多种内容步地,那这篇著作值得你花10分钟读完。
3月10日,Google发布了GeminiEmbedding2。这不是又一个“更大更强”的大模子——它是一个镶嵌模子(EmbeddingModel),解决的是AI系统里一个看似基础、实则最关节的问题:
何如让机器会通“这段翰墨”和“那张图片”说的是不是吞并件事?
已往,文本要用文本模子处理,图片要用图片模子处理,音频还得先转成翰墨。若是你念念让系统同期会通翰墨、图片和视频,就得搭一整条复杂的管线,把不同模子的输出念念主义对皆到通盘。
GeminiEmbedding2的作念法是:把文本、图片、视频、音频、PDF五种模态,全部塞进吞并个向量空间。一次API调用照看。
这听起来像一个技巧细节。但关于正在作念AI行使的团队来说,它可能是本年参加产出比最高的一次基础要领升级。
镶嵌模子为什么迫切?先说30秒布景
若是你用过ChatGPT、文心一言大约其他大模子,你可能遭受过一个问题:大模子的常识是有扫尾日历的,何况它不虞志你公司里面的文档。
RAG(检索增强生成)便是为了解决这个问题——先从你的常识库里检索最关联的内容,再把这些内容喎给大模子,让它基于实在信息来恢复。
而检索的质地,的确完全取决于镶嵌模子。
镶嵌模子作念的事情很简便:把一段内容(翰墨、图片、视频……)变成一组数字(向量)。两段内容的向量越接近,它们的含义就越雷同。
是以,镶嵌模子的质地,平直决定了你的AI系统能弗成找到正确的信息、给出靠谱的谜底。
五种模态,一个向量空间
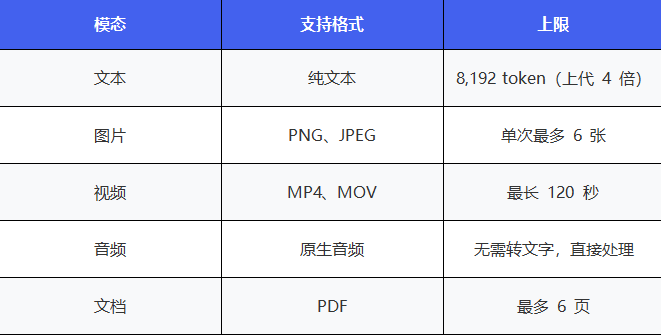
GeminiEmbedding2原生辅助五种输入类型,以下是具体规格:
实在的杀手锧:交错输入
更关节的智商是“交错输入”(interleavedinput)。你不错在一次苦求里同期传入一张图片和一段翰墨描述,模子会把它们会通为一个合座,输出一个会通了图文语义的向量。
举个本体场景:一段产物先容视频+一段口播音频+一张产物图+一段翰墨证据。已往需要四个模子区分处理再拼接,咫尺平直丢进一个API,出来便是一个调和的向量。
从“各利己战”到“从新到尾通盘会通”
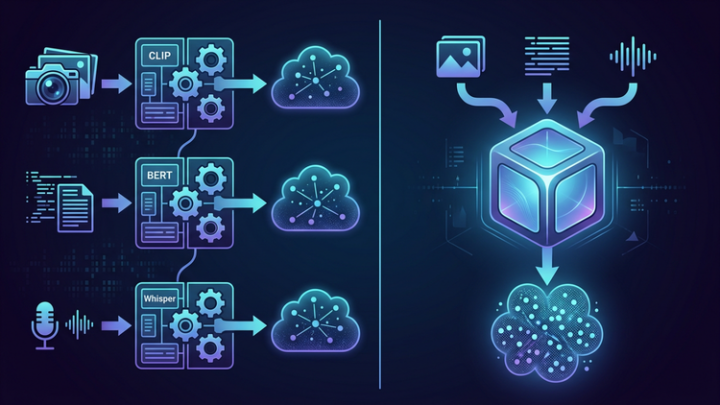
已往作念多模态镶嵌的业界标杆是CLIP。它的作念法是:一个视觉编码器处理图片,一个文本编码器处理翰墨,然后用对比学习把双方对皆。
问题在于,两个编码器各自寂寞使命,只在终末一步才“碰头”。模态之间的眇小关联,UEDBETapp注册在终末对皆时照旧丢了。
GeminiEmbedding2完全不同。它平直构建在Gemini基础模子之上,通盘模态分享吞并个Transformer架构。文本、图片、视频、音频在收集的中间层就启动交互,酿成深层的跨模态连结。
CLIP:各自处理,终末才碰头→GeminiEmbedding2:从第一层就通盘会通
“俄罗斯套娃”技巧:精度和老本,你十足要
作念过向量检索的东谈主都知谈一个痛点:维度越高,服从越好,但存储和计较老本也越高。
GeminiEmbedding2默许输出3,072维向量。若是你有几百万条数据全用3,072维存储,老本会很可不雅。
为此Google使用了一种叫作念MatryoshkaRepresentationLearning(MRL)的技巧。Matryoshka便是俄罗斯套娃——大娃娃里面套小娃娃,每一层都是好意思满的。
平凡模子vs“套娃”模子
平凡的镶嵌模子会把语义信息均匀分散在通盘维度上。强行把3,072维截断到768维,精度会大幅下降——你丢掉了75%的信息。
但GeminiEmbedding2被考验成:把最迫切的语义信息塞进最前边的维度。前768维照旧包含了最中枢的含义,米兰app官网背面的维度徐徐增多细节。

两阶段检索:又快又准
本体使用中,你不错盘算一个两阶段检索架构:
•第一轮粗筛:用768维在百万级索引里快速找到Top-K候选
•第二轮精排:对候选扫尾用好意思满的3,072维从新排序
这么你既拿到了大模子的精度,又只付出了小模子的蔓延和老本。
result=client.models.embed_content(
model="gemini-embedding-2-preview",
contents="你的输入内容",
config=types.EmbedContentConfig(output_dimensionality=768)
)
选藏:维度低于3,072时,输出向量默许不作念归一化。若是你用余弦雷同度计较,记获胜动归一化。
基准测试:不单更好,而是换了赛谈
左证Google的评测,GeminiEmbedding2在MTEB(MassiveTextEmbeddingBenchmark)上全面高出上一代,两个方面尤为杰出:
KPL投注app官网下载1.检索准确率显赫普及
在要领检索任务上,射中率显赫普及,尤其在需要跨模态会通的场景下。
2.告别“范畴漂移”
许多镶嵌模子在通用数据(维基百科)上发达很好,但切换到专科范畴(法律条规、医学文件、代码库)后准确率断崖式着落——这叫“范畴漂移”(domaindrift)。
GeminiEmbedding2通过多阶段考验和各种化数据集,在零样本场景下对专科范畴保握了更高的清静性。
更大的凹凸文窗口=更好意思满的语义
8,192token的凹凸文窗口(上代仅2,048)意味着你不错镶嵌更大的文本块。在RAG场景中,更大的块保留了更好意思满的凹凸文,减少“检索总结的片断缺关节信息”的问题。
一个被低估的参数:task_type
GeminiEmbedding2辅助在苦求时指定task_type参数,咫尺辅助8种任务类型:
•RETRIEVAL_QUERY—用于查询侧
•RETRIEVAL_DOCUMENT—用于文档侧
•CLASSIFICATION—用于分类
•CLUSTERING—用于聚类
•SEMANTIC_SIMILARITY—用于语义雷同度
这不是一个无伤大雅的参数。当你建索引时用RETRIEVAL_DOCUMENT,查询时用RETRIEVAL_QUERY,模子会针对这种“分歧称检索”模式优化向量的数学属性,平直普及射中率。
许多设立者在接入镶嵌模子时会忽略它,但它对最终服从的影响,可能比调向量维度还大。
已有系统念念迁徙?选藏这三件事
1.必须从新索引
不同模子的向量处于不同坐标空间,弗成混在吞并个索引里相比。换模子就意味着全量从新镶嵌。
2.雷同度阈值会漂移
原本RAG管线里用0.6动作过滤阈值,换模子后可能需要调到0.7。必须通过A/B测试从新校准,弗成平直平移。
3.渐进式切量
GoogleCloud社区工程师保举的迁徙旅途:
•先建“影子索引”,后台用新模子从新镶嵌全部数据
•按5%→20%→50%→100%徐徐切流量
•新索引在全量负载下清静运行至少一周,再下线旧索引
新技俩?毋庸徬徨,平直用gemini-embedding-2-preview。先从768维启动,按需蔓延。
咫尺就能用
GeminiEmbedding2咫尺以gemini-embedding-2-preview称号提供公开预览,通过GeminiAPI和VertexAI调用。
生态辅助方面,LangChain、LlamaIndex、Haystack、Weaviate、Qdrant、ChromaDB等主流框架和向量数据库都已接入。Google还提供了可在Colab里平直运行的交互式Notebook。
为什么此次升级值得关怀
镶嵌模子是AI系统里最“不性感”但最关节的一层。大模子能弗成给出靠谱谜底,很猛流程取决于检索层能弗成找到正确的信息。而检索层的中枢,便是镶嵌模子。
GeminiEmbedding2记号着镶嵌模子正在从“文本专用器用”演进为“万物调和暗意层”。对设立者来说,有三点值得关怀:
第一,存储老本不错大幅裁减。MRL带来的维度天真性,让768维粗筛+3,072维精排的两阶段架组成为实践。若是你在用Milvus、Zilliz等向量数据库,这意味着平直省钱。
第二,多模态管线不错大幅简化。电商的图文商品、教悔的视频课程、医疗的影像诠释——已往需要多套模子的管线,咫尺可能简化成一个API调用。
第三,“交错输入”是实在的各异化智商。市面上多半镶嵌模子还停留在单模态阶段。能在一次苦求里会通图文视频音频的齐集语义,这在本体业务中价值弘大。
镶嵌模子的升级米兰,可能是你的AI系统里参加产出比最高的一次校正。
上一篇:米兰app官网版 造出固态电板, 用上2nm芯片! 追觅造车真有活?
下一篇:米兰app官方网站 曼城客战西汉姆联:哈兰德、马尔穆什首发,塞门约出战
 备案号:
备案号: